
PocketPal
An iOS app for running local models

I’ve been using Twitter as a way to educate myself on AI and just keep adding people and companies, googling for more information on a person or a company, and then using ChatGPT-4o and Claude Sonnet 3.5 for more lengthy explanations. For example, I saw a reference yesterday to “loading the quantized GGUF to an endpoint” and had no idea what that meant.
GGUF is “GPT-Generated Unified Format” which is basically the file format for large language models. Like you would say PDF or jpeg, and an “endpoint” is a cloud service like Groq or Azure or AWS, more formally “a stable and durable URL that can be used to request or invoke a model.” At least according to Microsoft.
“Quantized” is a technique used to reduce the precision of the numbers used to represent the model’s parameters (weights and biases). Instead of using full 32-bit floating-point numbers, quantization uses lower precision representations, such as 16-bit, 8-bit, or even 4-bit integers.
You trade some precision for a smaller size, again like jpeg compression back in the old days of dial-up when we would have to adjust a picture to make it work on the slow web of the day and couldn’t count on the user’s software being able to make that adjustment efficiently (or at all).
So I was pretty blown away when I saw a Tweet by Awni Hannun fine-tuning the new Llama3.2-1b open source model on a iPhone 16 Pro and getting better than 150 tokens per second.
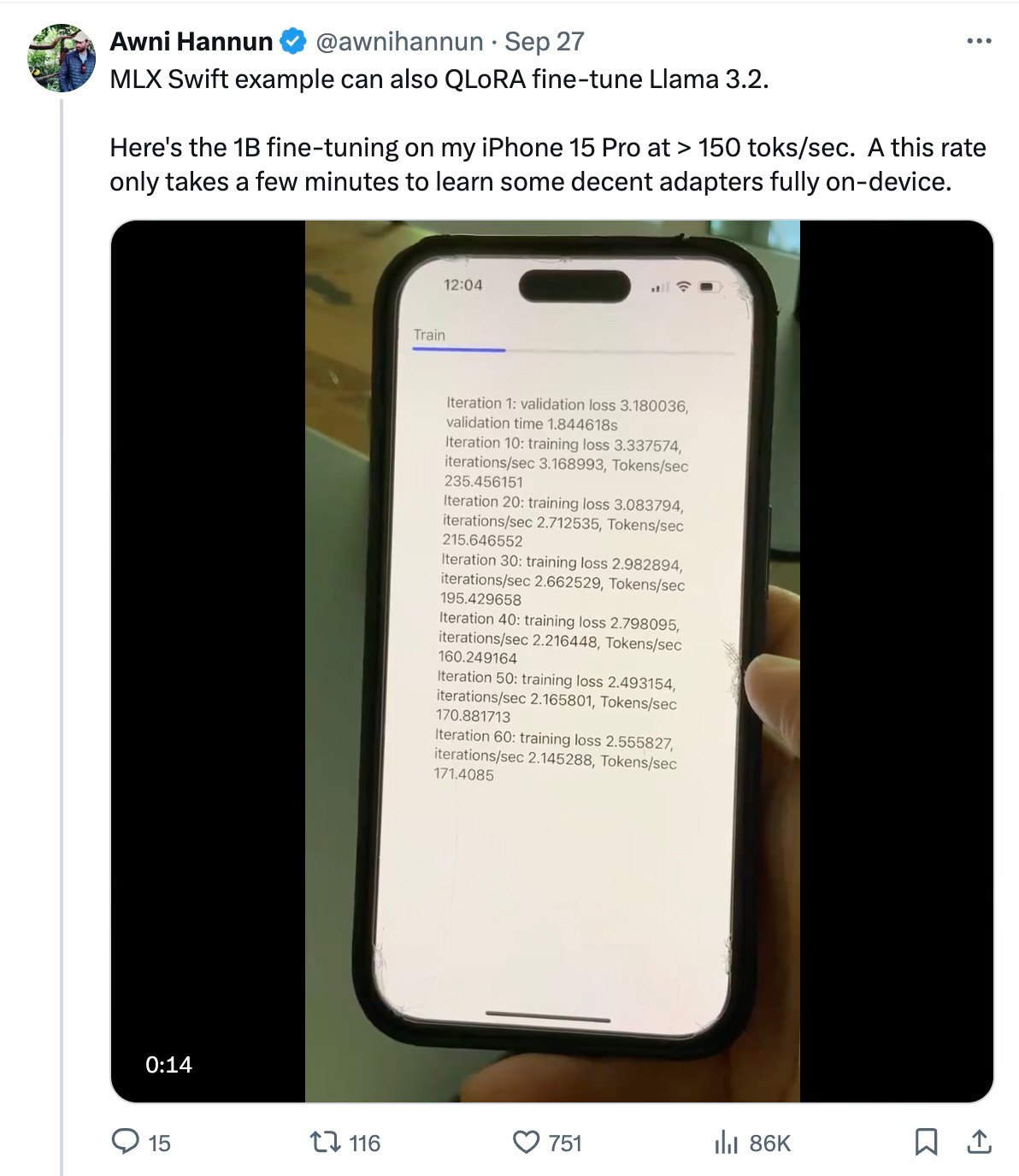
Impressive! No bozo, he’s one of the lead ML researchers at Apple and major contributor to MLX, the open source software that optimizes Apple Silicon for machine learning. He linked to mlx-swift which is a Github repo with the code to download and compile with XCode so I can make an app to run on my iPhone.
I thought I would try it. But before I could open my laptop and start working on XCode (which I haven’t run in maybe eight years) I saw a comment with someone suggesting PocketPal on the App Store. It’s similar, a wrapper around open source models that you can download.
I tried that and it works great, was able to run Llama3.2-3b-instruct — but only at 16 tok/sec. The output is a bit slow, way different from running Groq on the cloud at 2200 tok/sec for the Llama3.2-1b model. Oddly, the 1b model isn't available on PocketPal as far as I can tell.
But hey, a really useful generative AI model running entirely locally, without need of an internet connection, with performance that’s basically on par with state of the art models from less than a year ago. That’s how blazing fast this area is moving.